Seven Ways to Find Software Defects Before They Hit Production

Like this article? We recommend
Like this article? We recommend
Like this article? We recommend
Testing is a skill. It can be learned, and it improves with practice. This article provides a quick list of test ideas in seven techniques, along with hints of where to go for more:
- Quick Attacks
- Equivalence and Boundary Conditions
- Common Failure Modes
- State-Transition Diagrams
- Use Cases and Soap Opera Tests
- Code-Based Coverage Models
- Regression and High-Volume Test Techniques
Buckle up! We're going to start at the beginning and go very fast, with a focus on web-based application testing.
Technique 1: Quick Attacks
If you have little or no prior knowledge of a system, you don't know its requirements, so formal techniques to transform the requirements into tests won't help. Instead, you might attack the system, looking to send it into a state of panic by filling in the wrong thing.
If a field is required, leave it blank. If the user interface implies a workflow, try to take a different route. If the input field is clearly supposed to be a number, try typing a word, or try typing a number too large for the system to handle. If you must use numbers, figure out whether the system expects a whole number (an integer), and use a decimal-point number instead. If you must use words, try using the CharMap application in Windows (Start > Run > charmap) and select some special characters that are outside the standard characters accessed directly by keys on your keyboard.
The basic principle is to combine things that programmers didn't expect with common failure modes of your platform. If you're working on a web application with complex rendering code, try quickly resizing the browser window or flipping back and forth quickly between tabs. For a login screen (or any screen with a submit button), press Enter to see whether the page submits—it should.
For a short but dense list of quick attacks, look at Elisabeth Hendrickson's "Test Heuristics Cheat Sheet." For a longer introduction, consider How to Break Web Software: Functional and Security Testing of Web Applications and Web Services, by Mike Andrews and James Whittaker.
Strengths
The quick-attacks technique allows you to perform a cursory analysis of a system in a very compressed timeframe. Once you're done, even without a specification, you know a little bit about the software, so the time spent is also time invested in developing expertise.
The skill is relatively easy to learn, and once you've attained some mastery your quick-attack session will probably produce a few bugs. While the developers are fixing those bugs, you can figure out the actual business roles and dive into the other techniques I discuss in the following sections.
Finally, quick attacks are quick. They can help you to make a rapid assessment. You may not know the requirements, but if your attacks yielded a lot of bugs, the programmers probably aren't thinking about exceptional conditions, and it's also likely that they made mistakes in the main functionality. If your attacks don't yield any defects, you may have some confidence in the general, happy-path functionality.
Weaknesses
Quick attacks are often criticized for finding "bugs that don't matter"—especially for internal applications. While easy mastery of this skill is a strength, it creates the risk that quick attacks are "all there is" to testing; thus, anyone who takes a two-day course can do the work. But that isn't the case. Read on!
Technique 2: Equivalence and Boundary Conditions
Once you know a little bit about what the software should do, you'll discover rules about behavior and criteria. For example, think about an application that rates drivers for car insurance. Your requirements might say that drivers between the ages of 16 and 18 pay a certain rate, drivers 19 to 25 pay a different rate, and so on. It's easy enough to convert that information from an English paragraph into a chart, as shown in Figure 1. Of course, the real application would be much more complex than this chart, but you get the point.
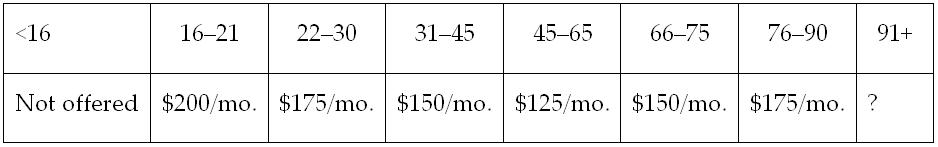
Figure 1: Example of automobile insurance cost per month, by age.
Just by looking at the table in Figure 1, you can probably spot a bug or two:
- What do we charge someone who's exactly 45 years old? I'll call this the "age 45 problem."
- We don't know how much to charge anyone who's 91 or older. The English paragraph we analyzed cut off at age 90.
Now, we could test every age from age 0 to 91—that gives us 91 test cases. In a real application, however, we'd have to perform each of those 91 tests multiplied by the number of points the driver has on his or her license, a variety of available discounts, perhaps types of coverage, or other variables. The number of test ideas grows exponentially, something we call the combinatorial explosion.
Equivalence classes say, "Hey, man, each column in the chart is the same. Just test each column once." Okay, it doesn't actually say that, but it's an attempt to point out that the data within a column might be equal, or equivalent. (Get it?) This principle allows us to test ages 5, 18, 25, 35, 55, 71, 77, and 93—getting all things that should be the same covered in 8 tests, not 91.
Notice I said that they should be the same. That's not necessarily the case.
Boundary testing is designed to catch the off-by-one errors, where a programmer uses "greater than" to compare two numbers, when he should have used "greater than or equal to." Boundary testing catches the "age 45 problem." In this example, we test every transition, both before and after: 15, 16, 21, 22, 30, 31, etc., so that all cases are covered.
Strengths
Boundaries and equivalence classes give us a technique to reduce an infinite test set into something manageable. They also provide a mechanism for us to show that the requirements are "covered" (for most definitions of coverage).
Weaknesses
The "classes" in the table in Figure 1 are correct only in the mind of the person who chose them. We have no idea whether other, "hidden" classes exist—for example, if a numeric number that represents time is compared to another time as a set of characters, or a "string," it will work just fine for most numbers. However, when you compare 10, 11, and 12 to other numbers, only the first number will be considered—so 10, 11, and 12 will fall between 1 and 2. Cem Kaner, a professor of software engineering at Florida Tech, calls this the "problem of local optima"—meaning that the programmer can optimize the program around behaviors that are not evident in the documentation.
Technique 3: Common Failure Modes
Remember when the Web was young and you tried to order a book or something from a website, but nothing seemed to happen? You clicked the order button again. If you were lucky, two books showed up in your shopping cart; if you were unlucky, they showed up on your doorstep. That failure mode was a kind of common problem—one that happened a lot, and we learned to test for it. Eventually, programmers got wise and improved their code, and this attack became less effective, but it points to something: Platforms often have the same bug coming up again and again.
For a mobile application, for example, I might experiment with losing coverage, or having too many applications open at the same time with a low-memory device. I use these techniques because I've seen them fail. Back in the software organization, we can mine our bug-tracking software to figure out what happens a lot, and then we test for it. Over time, we teach our programmers not to make these mistakes, or to prevent them, improving the code quality before it gets to hands-on exploration.
Strengths
The heart of this method is to figure out what failures are common for the platform, the project, or the team; then try that test again on this build. If your team is new, or you haven't previously tracked bugs, you can still write down defects that "feel" recurring as they occur—and start checking for them.
Weaknesses
In addition to losing its potency over time, this technique also entirely fails to find "black swans"—defects that exist outside the team's recent experience. The more your team stretches itself (using a new database, new programming language, new team members, etc.), the riskier the project will be—and, at the same time, the less valuable this technique will be.
Technique 4: State-Transition Diagrams
Imagine that your user is somewhere in your system—say, the login screen. He can take an action that leads to another place; perhaps his home page, or perhaps an error screen. If we list all these places and the links between them, we can come up with a sort of map through the application, and then we can build tests to walk every transition through the whole application. My colleague, Pete Walen, used these state transitions to discuss—and come up with test ideas for—a system-health meter on one project, as shown in Figure 2.
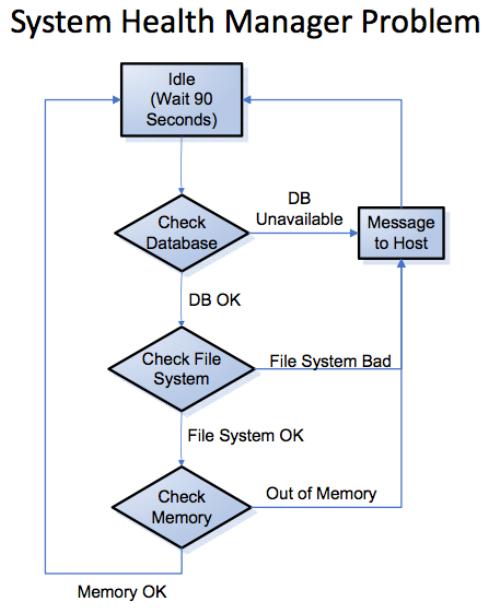
Figure 2: Walen's system health meter state diagram.
You can find more examples of state-transition diagrams, sometimes called finite state machines, in the lecture notes from Dr. John Dalbey's software engineering course at California Polytechnic University.
Strengths
Mapping out the application provides a list of immediate, powerful test ideas. You can also improve your model by collaborating with the whole team to find "hidden" states—transitions that might be known only by the original programmer or specification author.
Once you have the map, you can have other people draw their own diagrams (it doesn't take very long), and then compare theirs to yours. The differences in those maps can indicate gaps in the requirements, defects in the software, or at least different expectations among team members.
Weaknesses
The map you draw doesn't actually reflect how the software will operate; in other words, "the map is not the territory." In the example shown earlier in Figure 2, Pete tested all the transitions, but a subtle memory leak was discovered only by leaving the monitor on over a weekend. Drawing a diagram won't find these differences, and it might even give the team the illusion of certainty. Like just about every other technique on this list, a state-transition diagram can be helpful, but it's not sufficient by itself to test an entire application.
Technique 5: Use Cases and Soap Opera Tests
Use cases and scenarios focus on software in its role to enable a human being to do something. This shift has us come up with examples of what a human would actually try to accomplish, instead of thinking of the software as a collection of features, such as "open" and "save." Alistair Cockburn's Writing Effective Use Cases describes the method in detail, but you can think of the idea as pulling out the who, what, and why behaviors of system users into a description before the software is built. These examples drive requirements, programming, and even testing, and they can certainly hit the highlights of functional behavior, defining confirmatory tests for your application that you can write in plain English and a customer can understand.
Scenarios are similar, in that they can be used to define how someone might use a software system. Soap opera tests are crazy, wild combinations of improbable scenarios, the kind you might see on a TV soap opera.
Like quick attacks, soap opera tests can provide a speedy, informal estimate of software quality. After all, if the soap opera test succeeds, it's likely that simple, middle-of-the-road cases will work too.
Strengths
Use cases and scenarios tend to resonate with business customers, and if done as part of the requirement process, they sort of magically generate test cases from the requirements. They make sense and can provide a straightforward set of confirmatory tests. Soap opera tests offer more power, and they can combine many test types into one execution.
Weaknesses
One nickname for the tests that use cases generate is "namby pamby confirmatory"; they're unlikely to give the kind of combinatory rigor we would get from, say, equivalence classes and boundaries. If you try to get a comprehensive approach with these techniques, you'll likely fail, and you'll overwhelm your business users with detail. Soap opera tests have the opposite problem; they're so complex that if something goes wrong, it may take a fair bit of troubleshooting to find exactly where the error came from!
Technique 6: Code-Based Coverage Models
Imagine that you have a black-box recorder that writes down every single line of code as it executes. You turn on this recorder when you start testing, turn it off when you're finished, and then look at it while lines of code are untested ("red"); then you can improve your testing of the red functions and branches. Tools exist to do exactly this, both at the unit-test level (Clover) and the customer-facing test level (McCabe IQ).
The level I describe above is called statement coverage, and it has limits. Consider, for example, two IF statements with a line of code in each. I might be able to run one test that covers all the code, but there could be defects if only the first, only the second, or none of those IF statements is executed. There are many other ways to measure how much code is executed by tests, such as branch coverage (which would cover all four cases) or decision coverage (which looks at every possible criteria of the OR, AND, and XOR statements within the decision whether to branch.
Strengths
Programmers love code coverage. It allows them to attach a number—an actual, hard, real number, such as 75%—to the performance of their unit tests, and they can challenge themselves to improve the score. Meanwhile, looking at the code that isn't covered also can yield opportunities for improvement and bugs!
Weaknesses
Customer-level coverage tools are expensive, programmer-level tools that tend to assume the team is doing automated unit testing and has a continuous-integration server and a fair bit of discipline. After installing the tool, most people tend to focus on statement coverage—the least powerful of the measures. Even decision coverage doesn't deal with situations where the decision contains defects, or when there are other, hidden equivalence classes; say, in the third-party library that isn't measured in the same way as your compiled source code is.
Having code-coverage numbers can be helpful, but using them as a form of process control can actually encourage wrong behaviors. In my experience, it's often best to leave these measures to the programmers, to measure optionally for personal improvement (and to find dead spots), not as a proxy for actual quality.
Technique 7: Regression and High-Volume Test Techniques
So today's build works, and you deploy. That's great! But tomorrow we'll have a new build, with a different set of risks. We need to prove out the new functionality and also make sure that nothing broke—at least, to the best of our knowledge. We want to make sure that the software didn't regress, with something failing today that worked yesterday.
People spend a lot of money on regression testing, taking the old test ideas described above and rerunning them over and over. This is generally done with either expensive users or very expensive programmers spending a lot of time writing and later maintaining those automated tests.
There has to be a better way! And often there is.
If your application takes a set of input that you can record, and it produces any sort of output that you can record, you can collect massive amounts of input, send it to both versions of the app, and then gather and compare the output. If the output is different, you have a new feature, a bug, or...something to talk about.
If you're not into regression testing, but you can at least build a model of that inner core behavior, it might be possible to generate random input and compare the actual result to the expected result. Harry Robinson, Doug Hoffman, and Cem Kaner are three leaders in this field, sometimes called high-volume test automation. Harry Robinson has a good presentation describing one implementation of this approach at Bing.
Strengths
For the right kind of problem, say an IT shop processing files through a database, this kind of technique can be extremely powerful. Likewise, if the software deliverable is a report written in SQL, you can hand the problem to other people in plain English, have them write their own SQL statements, and compare the results. Unlike state-transition diagrams, this method shines at finding the hidden state in devices. For a pacemaker or a missile-launch device, finding those issues can be pretty important.
Weaknesses
Building a record/playback/capture rig for a GUI can be extremely expensive, and it might be difficult to tell whether the application hasn't broken, but has changed in a minor way. For the most part, these techniques seem to have found a niche in IT/database work, at large companies like Microsoft and AT&T, which can have programming testers doing this work in addition to traditional testing, or finding large errors such as crashes without having to understand the details of the business logic. While some software projects seem ready-made for this approach, others...aren't. You could waste a fair bit of money and time trying to figure out where your project falls.
Combining the Techniques
When I look at the list of techniques described above, I see two startling trends. Some of the tests can be easily automated, even tested by the programmers below the graphical level or covered by unit tests. Others are entirely business-facing, and they show up only when a human being uses the application, sends paper to the printer, or views a specific kind of rendering error in an ancient version of Internet Explorer. Some of the test ideas overlap (you could have a scenario that tests a specific boundary condition), while others are completely unrelated.
This article has focused on generating test ideas. Now that we have the set (which is nothing compared to the set of possible inputs and transformations), we have a few challenges:
- Limit ideas to ones that will provide the most information right now
- Balance the single test we could automate in an hour versus the 50 we could run by hand in that hour, to figure out what we learned in that hour and how to report about it
I call this the "great game of testing": The challenge is how to spend our time and come to conclusions about a system that's essentially infinite.
Go dive into the great game of testing. Have some fun.
Play to win.